CPC故事丨西安交通大学“Cyberpunk6031队”
经过3年的不懈努力,非常幸运的拿到了第五届CPC竞赛的冠军。这个成绩离不开参赛队员之间的分工与协作,更离不开高性能计算团队全方位的支持。连续3年的参赛,锻炼了队伍,提升了学生的科研能力。我能深刻的体会到竞赛源于科研,竞赛反哺科研,也希望更多的高校参与到CPC竞赛,为国内的高性能计算生态培养更多的人才。
---指导老师 陈衡

我们是来自西安交通大学的Cyberpunk6031,非常庆幸能够参加第五届“神威杯”国产CPU并行应用挑战赛,并且能够在本届竞赛中取得优异成绩。之所以叫Cyberpunk6031,只是因为现在的实验室在6031,我们前两年参加的队伍名一直叫404扛把子,也是因为当时的实验室在404。
高性能计算一直是西安交通大学计算机科学与技术学院的重点研究领域,依托于计算机学院的新型计算机,研究所一直也是在这个领域下进行科学研究。从2019年开始,高性能计算团队开始参加国内的高性能计算比赛,比赛团队由董小社、张兴军教授、陈衡老师和李靖波博士带领,并由实验室的研究生组建的学生科技团队参赛,本届竞赛能够荣获好的成绩,离不开指导老师的悉心指导,同时团队师兄也传授给了我们很多参赛的宝贵经验。

积累一直是高性能计算研究中的至关重要的一个环节。我们的队伍是由研究生组成的,这意味着我们有着更多机会接触高性能计算和众多研究热点,比如人工智能相关的知识。但是科学研究毕竟和比赛不同,参赛经验也是必不可少。我们团队自2019年参加CPC以来,也积累了一些比赛经验,最为重要的就是:针对每一位队员的时间、精力定制比赛攻略,成了必须要重视的事情。



2019-2021
但是,不同于本科的是,研究生大多数都需要承担科研与项目压力,怎么在比赛和科研之间建立平衡成了一件非常重要的事情。比赛队伍由一个老队员和三个新队员参加,由于老队员具备比赛相关的知识,因此我们决定采用实战排练的方式来针对新队员进行训练,让三个新队员独自负担初赛题目,老队员依然专心科研。并在最终,采用四个人同时全力比赛的方式来弥补之前知识上的不足。

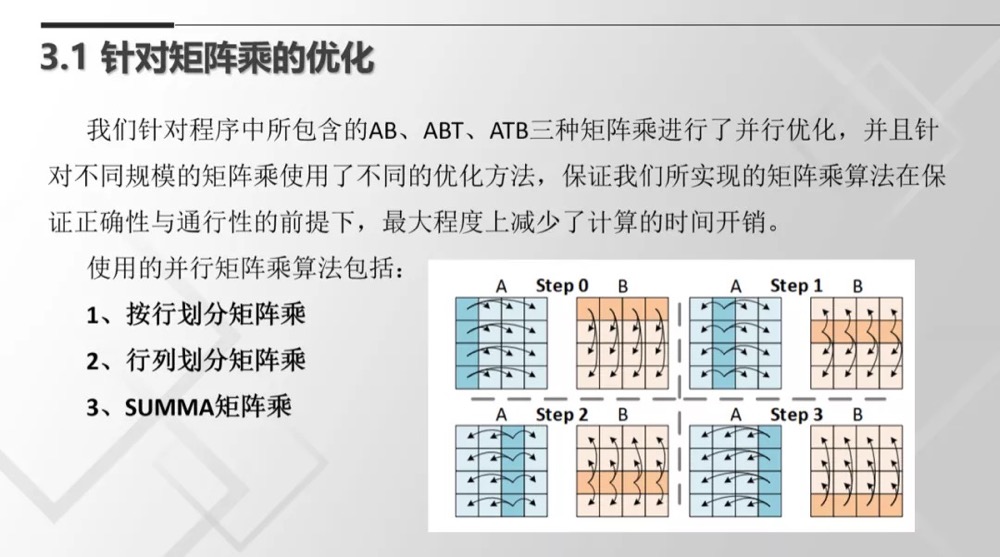
本次决赛紧扣Transformer这一深度学习前沿网络和相关应用热点,要求我们在新一代申威众核架构下,优化基于PyTorch实现的ViT模型训练任务,并针对其中的Transformer结构进行性能优化。我们四位队员进行了细致分工,包括基于神威处理器的SUMMA算法实现、cache局部性矩阵乘优化、LDM内存管理、数学库函数加速、PyTorch算子C语言并行化、多头机制特异性优化、核间RMA协同设计和向量化与指令级并行等。在保证模型精度和准确度的基础上,对多种训练规模的参数均进行了针对性优化。经过一系列的并行优化,单节点性能相比于原始版本,提升了数百至数千倍,同时在多节点上也有良好的可扩展性。
在整体上,我们为了消去从核启动开销,全面实现从核并行化,将代码全部集成到一个从核函数内部,为了避免内存管理带来的问题和开销,我们自行设计了内存管理部件,几乎完全消去了内存管理开销。在将pytorch代码完全c语言化的过程中,有很多出乎我们意料的问题。为了提高程序的性能,我们采用了新的RMA技术。同时,针对不同的矩阵大小,我们还设计了针对化的数据重用策略,这些方法对于小矩阵尤其有用。新神威芯片的LDM增大,给我们的矩阵优化策略带来了很多便利。我们还对数学函数exp进行了优化,优化策略和2018年决赛的优化方法类似,这部分的开销源于函数调用开销,当使用宏替换后,开销明显减小。我们还对向量化以及指令集并行做了尝试,最终发现指令集并行带来的提升不大,但是会影响程序可读性,因此仅部署了向量化方案。

最终我们的设计经受住了大量数据集的考验,同时具备了加速能力与算法鲁棒性。
在每届比赛中,最为难忘的经历往往就是无锡酒店的熬夜调代码经历。从2019年以来,总是会有两个夜晚无法安然入眠,这是我们团队比赛的传统,也是我们对高性能计算的执着。
欢迎大家分享自己的参赛感想、故事、收获或想对CPC说的话。

- 扫码关注 -
微信号| CPC-HPC
国产CPU并行应用挑战赛
官方通知

2026/6/8


2026/5/26

2026/5/25

2026/5/15

2026/5/10

2026/5/8


2026/5/8


2026/5/8

2025/11/6

2025/8/30

2025/8/15

2025/8/5

2025/7/25

2025/7/25

2025/7/24

2025/6/21

2025/6/9
11月24